
AI Document Processing: A Guide to Better RAG Retrieval
Unlock your data's potential with this guide to AI document processing. Learn practical strategies for chunking, embedding, and retrieval to boost RAG accuracy.

Before you can build a powerful AI application, you first have to make sense of your data. For Retrieval Augmented Generation (RAG) systems, AI document processing is the critical first step of turning messy, raw files into structured, high-quality information that enables precise retrieval. This process is the engine that powers everything from automated invoice handling to sophisticated Q&A bots that deliver accurate, source-grounded answers.
The Foundation of High-Fidelity RAG Systems

Many teams dive into building Retrieval Augmented Generation (RAG) systems thinking they can just point the AI at a folder of PDFs and get great answers. That approach almost never works. Instead, they end up with irrelevant retrieved context, missed information, and the dreaded "hallucinations."
Why? Because the quality of what comes out of a RAG system is a direct reflection of the quality of the data it retrieves.
Think of AI document processing as preparing your knowledge base for an expert researcher (the RAG system). If documents are just thrown into a pile, the researcher won't find the specific facts they need. But if you carefully parse, clean, and chunk everything, the researcher can instantly pinpoint the exact passage required to answer a question. This foundational work transforms a messy data dump into a reliable, searchable knowledge base optimized for retrieval.
The old saying "garbage in, garbage out" has never been more true. If you feed an LLM poorly structured, noisy, or irrelevant context, you will get low-quality answers. High-fidelity retrieval starts long before a user ever asks a question.
Why Meticulous Preparation Matters for Retrieval
Good document processing isn't just about ripping text out of a file. It's about meticulously preserving the original context and structure to create chunks that are optimized for retrieval. A simple text dump loses the crucial relationships between headings, paragraphs, and tables—the very clues a RAG system needs to find relevant information and an LLM needs to generate nuanced, accurate responses.
Proper preparation ensures that:
- Context is Preserved: Information is broken down into logical, self-contained chunks that represent complete ideas.
- Noise is Removed: Useless artifacts like page numbers and headers that can confuse retrieval models are scrubbed clean.
- Retrieval is Optimized: The data is structured in a way that makes it dead simple for the RAG system to find the most relevant passage for a given query.
This methodical approach is catching on fast. The Intelligent Document Processing market was valued at USD 7.89 billion and is expected to explode to USD 66.68 billion by 2032, growing at a compound annual rate of 30.1%. You can dig into more of these document processing statistics and market growth on sensetask.com.
How Raw Documents Become AI-Ready Knowledge
Getting a raw file, like a PDF or Word document, ready for a RAG system is a multi-step process. It transforms a static, messy document into a clean, structured, and searchable knowledge base. Think of it as a refinery for information, where each stage purifies and prepares the content for precise AI retrieval.
This entire pipeline is the engine behind what we call AI document processing.
It all starts with getting the text out. If you're dealing with a scanned document or an image, you'll first need Optical Character Recognition (OCR) to turn the picture of text into actual, machine-readable characters. From there, the system must parse the document to understand its layout—identifying headings, lists, tables, and paragraphs.
This initial extraction is a critical first step. If you want to get into the nuts and bolts of it, we have a whole guide on how to perform Python PDF text extraction that walks you through the process.
From Text to Meaningful Vectors
Once the raw text is out, the real cleanup begins. This is where you strip away all the distracting "noise"—things like headers, footers, and page numbers that don't add meaning and can pollute your vector search results. You need clean, structured text before you can move on to creating embeddings.
This is where the magic really happens. Semantic embeddings are the core of modern AI retrieval. An embedding model converts your clean text into a string of numbers called a vector. Think of it as giving every chunk of text a specific coordinate on a massive, multidimensional map of language.
The real power here is that concepts with similar meanings end up close to each other on this map. The vectors for "quarterly earnings report" and "financial performance summary" will be neighbors, enabling the RAG system to find relevant information even if the user's query uses different words.
This is how the AI moves beyond simple keyword matching and starts to grasp the actual meaning behind the words, which is the key to effective retrieval.
Indexing for Instant Retrieval
So now you have a bunch of vectors representing the concepts in your document. You need to store them in a way that makes them easy to find. This is where a Vector Database comes in.
Unlike a regular database, a vector database is built for one thing: finding the vectors that are closest to a user's query vector. It’s a search based on conceptual similarity, not just keywords.
Here’s the actionable workflow for retrieval:
- User Query: A user asks a question, like, "What were the company's key financial highlights last year?"
- Query Embedding: The RAG system instantly converts that question into its own vector.
- Similarity Search: The vector database then zips through millions of document vectors to find the ones that are mathematically closest to the user's query vector.
- Context Retrieval: The original text chunks linked to those top-matching vectors are pulled out and handed to the LLM, giving it the precise context it needs to formulate a great answer.
Every stage, from OCR and parsing to cleaning and indexing, builds on the one before it. The end result is a highly organized, semantically-rich knowledge base that can power genuinely accurate and context-aware RAG systems.
Choosing the Right Document Chunking Strategy
Once your documents are cleaned and parsed, you hit what’s arguably the most critical step for tuning your RAG system’s retrieval performance: document chunking.
Think of it like creating a detailed index for a book. Instead of forcing the AI to read the entire volume every time, you’re breaking the content down into meaningful, self-contained sections it can quickly reference. It’s all about finding the sweet spot.
The goal is to create chunks that are contextually complete without being so large they dilute the core message. Getting this balance right is central to effective AI document processing, because the quality of your chunks directly dictates the quality of information your RAG system retrieves. Better chunks mean more precise context, which leads to more accurate answers.
This flowchart lays out the high-level workflow, from the initial scan to the final indexing, that gets documents ready for chunking and retrieval.
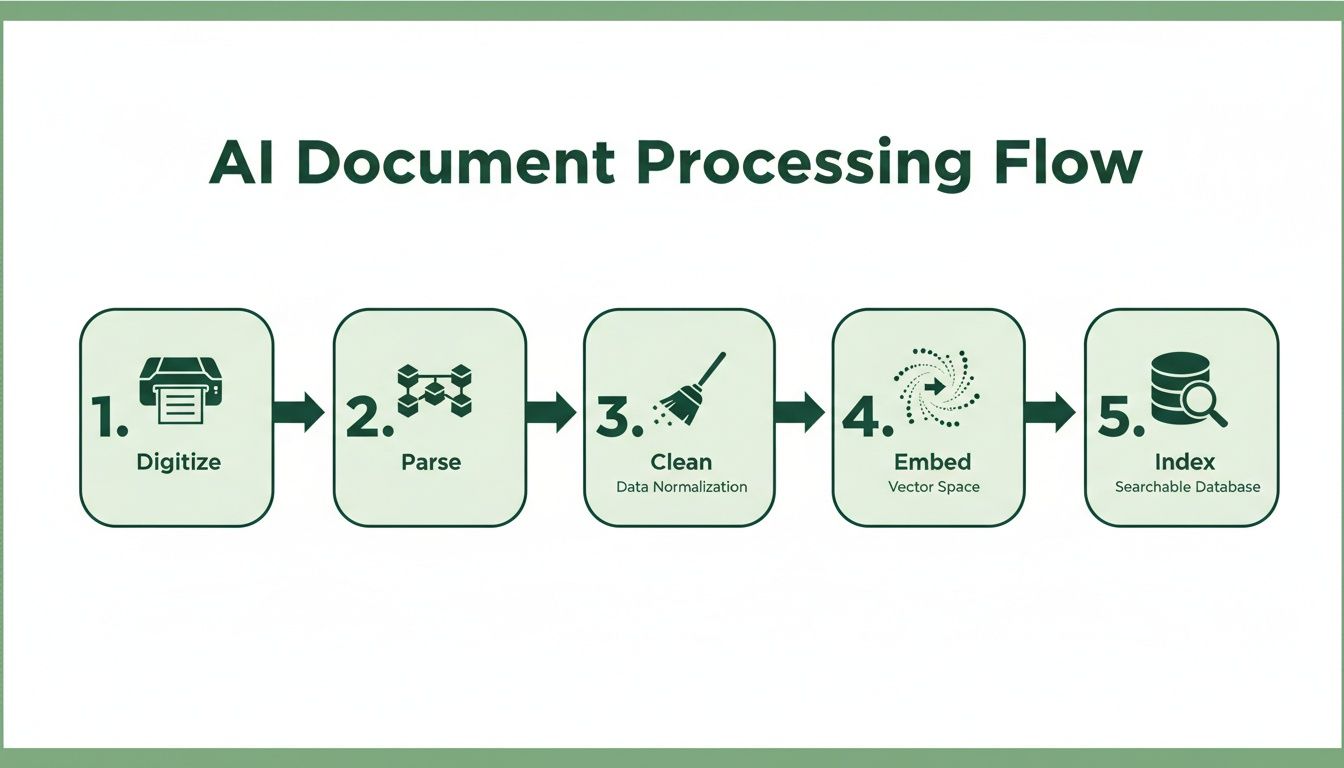
Each step here systematically refines the raw document. By the time you index the final chunks, the data is clean, structured, and perfectly optimized for semantic search.
Comparing Document Chunking Strategies for RAG
Not all documents are created equal, so a one-size-fits-all chunking strategy is rarely the answer. The method you pick should match the structure of your source material to maximize retrieval relevance. Let’s walk through the most common approaches.
This table breaks down the main chunking strategies, helping you see at a glance how they work and where they shine for RAG.
| Strategy | How It Works | Best For | Pros | Cons |
|---|---|---|---|---|
| Fixed-Size | Slices text into uniform chunks (e.g., 512 tokens) with optional overlap. | Unstructured text or as a simple baseline. | Simple, fast, and predictable. | Often splits sentences and ideas, destroying context. |
| Paragraph-Based | Splits the document along natural paragraph breaks. | Narrative content like articles, reports, and books. | Preserves semantic meaning within a single thought. | Paragraph sizes can be inconsistent, leading to overly large or small chunks. |
| Heading-Based | Groups text under its corresponding heading or subheading. | Highly structured documents like legal contracts or technical manuals. | Maintains the document's logical hierarchy and context. | Can result in massive chunks if sections are very long. |
| Semantic | Uses embedding models to find natural breaks where the topic shifts. | Dense, complex documents with subtle topic changes. | Creates thematically pure chunks with high contextual relevance. | Computationally more expensive and slower than other methods. |
Ultimately, the best strategy depends entirely on your documents. For a simple text file, fixed-size might be fine. But for a complex technical manual, a heading-based or semantic approach will give you far better retrieval results.
Simple vs. Advanced Chunking Strategies
Let's dig into the actionable differences between these methods. The simplest approach, Fixed-Size Chunking, just chops text into chunks of a set length (say, 512 tokens). It’s a decent baseline, but its biggest flaw is that it has no respect for grammar or meaning—it will happily slice a sentence right down the middle, making the resulting chunk less useful for retrieval.
A more effective approach is Paragraph-Based Chunking. This strategy splits the document along natural paragraph breaks. Since paragraphs usually contain a single, cohesive idea, this method does a far better job of keeping semantic meaning intact. It’s a solid choice for narrative documents like articles or reports.
The ultimate goal of chunking is to maximize contextual relevance within each chunk. You want just enough information for the RAG system to identify it as relevant, but not so much that the key details are lost in noise.
But for more complex documents, you need advanced strategies to get the precision required for high-fidelity retrieval.
Heading-Based Chunking is perfect for documents with a clear hierarchy, like technical manuals. It works by grouping text under its corresponding heading, making sure that any retrieved chunk contains the full context of that specific section. This stops the system from pulling a random paragraph without its orienting title.
Then there’s Semantic Chunking, which uses embedding models to find natural topic shifts. It groups sentences based on their conceptual similarity, creating chunks that are thematically pure. This is a game-changer for dense documents where topics shift subtly. You can take a much deeper look into these methods in our detailed guide to chunking strategies for RAG.
Fine-Tuning Retrieval to Find Better Answers
<iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube.com/embed/lYxGYXjfrNI" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>Once your documents are expertly chunked and indexed, the next challenge is retrieval—the art of finding the perfect context to answer a user's question. Think of it as a highly skilled librarian who understands the intent behind a query, not just the keywords. A simple similarity search is just the beginning.
To build a RAG system that feels truly intelligent, you need actionable techniques to ensure the best possible context gets sent to the LLM.
Going Beyond Basic Similarity Search
One of the most effective methods is hybrid search. This combines the conceptual understanding of vector search with the precision of keyword search. This is a game-changer for queries that include specific product names, error codes, or acronyms that a purely semantic search might misunderstand. By blending the two, you can catch both "what it means" and "what it says," dramatically improving retrieval accuracy.
Another crucial layer is re-ranking. After your initial search pulls a set of potential candidates (say, the top 20 matches), a re-ranking model takes a closer look. This more sophisticated model scrutinizes this small group of results against the user's query and shuffles them into a new order, pushing the absolute best chunks to the very top. This two-step process delivers much higher precision without the computational cost of running a heavy-duty model over your entire database.
The goal of advanced retrieval is to build the most information-rich, concise, and relevant context possible. Better retrieved context is the single best way to reduce LLM hallucinations and improve answer quality.
Enhancing Queries to Capture User Intent
Sometimes, the problem isn't the search—it's the user's question. A query might be too short or ambiguous. Query transformation techniques fix this by sharpening the user's input before it ever hits your vector database.
-
Query Expansion: This technique automatically adds synonyms or related concepts to the original query. A search for "Q3 earnings" could be expanded to include "third-quarter financial results." This casts a wider, smarter net to catch all relevant document chunks.
-
Query Decomposition: When a question is complex, this method breaks it down into several smaller, simpler sub-questions. The system then finds documents for each piece and stitches the context together, giving the LLM a more comprehensive foundation to build its answer on.
These advanced retrieval strategies are quickly becoming standard practice. The adoption of AI for document processing is exploding, with 63% of Fortune 250 companies having already deployed solutions. The financial sector is at the forefront with a 71% adoption rate, a clear sign of the real-world value these systems deliver. You can learn more about the growth of intelligent document processing on docsumo.com. By moving beyond basic search, these companies ensure their AI investments pay off with accurate, reliable answers.
Putting It All Together: A Real-World Document Processing Workflow

Theory is great, but seeing how the pieces fit together is what really matters. Let’s build a production-ready AI document processing pipeline designed specifically to improve RAG retrieval.
Imagine we've been handed a complex, 100-page annual financial report. Our goal is to prep it for a RAG application so users can ask specific questions about the company's performance. Here is an actionable blueprint for turning that raw PDF into a smart, queryable knowledge base.
Step 1: Ingestion and Parsing
First, we ingest the PDF. This document has a clear hierarchy. Instead of just ripping the text out, a sophisticated parser maps the document's structure, identifying headings, subheadings, paragraphs, and tables. It knows that "Section 1: Financial Highlights" is the parent of all the content that follows until "Section 2" begins. This structural map is the foundation for creating retrieval-optimized chunks.
Step 2: Applying a Heading-Based Chunking Strategy
Now we apply a heading-based chunking strategy. We're going to group content under its parent heading, creating chunks that are logically complete. For example, the entire discussion of "Q4 Revenue Growth," including its introductory text and supporting figures, becomes one cohesive chunk.
This ensures that when a user asks about fourth-quarter performance, the RAG system retrieves the whole story. The chunk contains the heading for context, the explanatory paragraphs, and any related data. It's a simple but powerful way to ensure retrieved context is complete.
A visual tool like ChunkForge is a lifesaver here. It gives you a direct overlay, mapping every chunk back to its source pages. You can instantly see if a split makes sense, spot bad breaks, and trace any retrieved context straight back to the original document.
That kind of immediate feedback loop lets you fine-tune your chunking rules on the fly to improve retrieval outcomes.
Step 3: Metadata Enrichment and Indexing
Next, we enrich each chunk with metadata. We can automatically generate a summary for each chunk, extract keywords, and tag it with its location in the document hierarchy (e.g., section: "Financial Highlights", subsection: "Q4 Revenue Growth").
This metadata becomes a powerful filtering tool during retrieval. A user could ask, "What were the revenue drivers in the financial highlights section?" and the system can pre-filter the search space to only those chunks with the correct metadata tag before performing the vector search.
Finally, we convert these enriched chunks into embeddings and load them into a vector database. The combination of semantic search and precise metadata filtering creates an incredibly robust retrieval pipeline.
To see how all these components work together in a bigger system, check out our guide to building a complete RAG pipeline from scratch.
Production Considerations: Efficiency and Privacy
When you move from a prototype to a real-world system, two things become non-negotiable: efficiency and privacy.
Processing thousands of documents demands a scalable setup. This often means using a serverless architecture where you can spin up parallel jobs to handle high volumes without having to manage the underlying infrastructure.
For sensitive files like financial reports, data privacy is everything. Self-hosting your pipeline with open-source tools like ChunkForge gives you absolute control. No proprietary data ever has to leave your secure environment—a must-have for any serious enterprise application.
Evaluating Performance and Avoiding Common Mistakes
Building a slick AI document processing pipeline is one thing. Knowing if it actually improves retrieval is another. Without the right metrics, you’re flying blind. You might push a change you think is an improvement, only to silently degrade retrieval performance. Success has to be measured.
To get a real sense of your RAG system's retrieval effectiveness, you need a solid evaluation framework. This means creating a test set of questions where you already know the "golden" answers from your documents. You run these questions through your pipeline and track key metrics to get an objective score.
Key Retrieval Metrics to Track
Three core metrics will give you a clear picture of your retrieval system's health:
-
Hit Rate: What percentage of the time did your system retrieve the correct document chunk needed to answer the question? A high hit rate is the first sign that you're on the right track.
-
Mean Reciprocal Rank (MRR): MRR adds nuance. It doesn't just care if you found the right chunk, but where it appeared in the list of results. It rewards systems that put the best answer right at the top.
-
Context Precision: Of all the chunks you retrieved, what percentage were actually relevant to the question? High precision means you're giving the LLM a clean, focused context instead of cluttering it with junk.
The real goal here is to build a tight feedback loop. When you can systematically track these metrics, you can confidently try a new chunking strategy or a different embedding model and know for certain what impact it had on retrieval.
Common Pitfalls That Undermine RAG Systems
Even with careful planning, a few classic mistakes can completely sabotage your retrieval accuracy. One of the biggest offenders is the "lost-in-the-middle" problem, where critical information gets buried deep inside a massive chunk and the LLM just glazes over it. This is a direct symptom of poor chunking.
Another killer is a mismatched embedding model. If you use a generic model trained on web pages to index highly specialized legal or medical documents, it simply won't grasp the nuances of the language, leading to poor retrieval.
Finally, there’s poor metadata management. Failing to tag your chunks with their source document or section makes it impossible to use powerful filtering techniques or trace an answer back to its origin, which is a massive blow to trust and usability.
Common Questions About AI Document Processing
Let's tackle some of the most common questions about building a document processing pipeline for RAG. These are the actionable insights you need to improve retrieval.
What's the Single Most Important Factor for Good RAG Performance?
While every part of the pipeline plays a role, document chunking consistently emerges as the most critical piece of the puzzle for enabling high-quality retrieval.
If your chunks are bad—splitting ideas in half or missing key context—your retrieval system has no chance of finding the right information to send to the LLM. That’s the fast track to inaccurate answers. A smart chunking strategy that respects the meaning of your content is the foundation for high-fidelity retrieval.
Can I Just Use the Same Chunking Strategy for All My Documents?
You could, but your retrieval quality will suffer. A simple, fixed-size chunking strategy might work for plain text files, but it will fall apart with more complex, structured documents.
Think about the difference between a blog post and a legal contract. Forcing them into the same chunking mold ignores their unique structures. Tailoring your approach—like using heading-based chunking for a report or semantic chunking for dense technical papers—will always produce better retrieval results.
How Should I Handle Tables and Images for Retrieval?
Tables and images are notorious for tripping up basic text extractors, leading to poor retrieval. You need a specialized approach.
For tables, the best practice is to extract them as structured data. Convert them to something clean like Markdown or a CSV snippet and embed this representation. This gives the model a clear, organized format to search over instead of a jumbled mess of text.
For images, you have a couple of solid options to make them retrievable:
- Use an image-to-text model to generate a rich, descriptive caption that can be embedded.
- Lean on multi-modal embeddings that capture the visual information of the image numerically.
You can then attach this new metadata to the surrounding text chunks. This gives your RAG system a much more complete and accurate understanding of the original document.
Ready to build a smarter RAG pipeline? ChunkForge gives you the tools to create contextually aware, retrieval-ready chunks from any document. Start your 7-day free trial and see the difference precise chunking makes.