
A Developer's Guide to the Haystack Search Engine for RAG
Build smarter RAG systems with our guide to the Haystack search engine. Learn to create advanced retrieval pipelines and improve search accuracy.

Let's get one thing straight: Haystack isn't a search engine you use like Google. Instead, it's a powerful, open-source framework that gives you the building blocks to create your own intelligent search systems, specifically tailored for Retrieval-Augmented Generation (RAG). Think of it as the high-performance "plumbing" that connects your private data to the reasoning power of Large Language Models (LLMs), letting you build advanced, data-grounded AI applications.
What Is the Haystack Search Engine

Traditional search is a keyword-matching game. You type "annual revenue report," and it finds documents with those exact words. This method fails when the answer lies in a document that uses synonyms like "yearly financial statement."
This is where the Haystack framework changes the game for RAG systems. It’s built for semantic search, which focuses on the meaning and intent behind your query, not just keywords.
That capability is the secret sauce for modern AI systems, especially those using Retrieval-Augmented Generation (RAG). Instead of just relying on an LLM’s built-in knowledge—which can be outdated or generic—Haystack lets you ground its answers in your own up-to-date, specific information. This ensures the LLM receives the most accurate context possible to generate a reliable answer. If you're new to the concept, our guide on Retrieval-Augmented Generation is a great place to start.
Powering Next-Generation RAG Systems
At its core, Haystack is a modular toolkit for building sophisticated data pipelines optimized for RAG. These pipelines are the assembly lines of your system: they ingest documents, process them into a format AI models can understand, retrieve the most relevant information for a given query, and then feed that context to an LLM to generate a precise, factual answer.
The entire framework is designed to give you granular control over the retrieval process, which is the most critical component for RAG performance.
For instance, you could use Haystack to build a system that:
- Answers employee questions by retrieving specific clauses from internal HR policies.
- Acts as a support chatbot by finding exact troubleshooting steps in complex product manuals.
- Summarizes legal contracts by first retrieving key clauses before generating a synopsis.
To help you get a clearer picture, here's a quick summary of what Haystack brings to your RAG stack.
Haystack Framework at a Glance
| Concept | Description | Primary Use Case |
|---|---|---|
| Modular Framework | A collection of customizable components (nodes) for building data pipelines. | Creating flexible and powerful RAG and semantic search applications. |
| Pipeline-Driven | Chains together different processing steps, like retrieval, ranking, and generation. | Orchestrating complex RAG workflows from user query to final answer. |
| LLM-Agnostic | Integrates with various models from providers like OpenAI, Cohere, and Hugging Face. | Avoiding vendor lock-in and choosing the best model for the job. |
| Data-Centric | Designed to connect LLMs with your private data sources (files, databases, APIs). | Building AI systems that provide answers based on your specific knowledge base. |
Ultimately, Haystack is about empowering developers to build intelligent systems that can reason over private data. The quality of that reasoning depends entirely on the quality of the retrieved information.
It's telling that Google holds a staggering 90.63% of the global search market share. That dominance shows how powerful a finely tuned information retrieval system can be. Haystack brings that same philosophy of precision and relevance to your custom data, letting you build specialized RAG applications that genuinely understand and find what users are asking for.
Understanding Haystack's Core Architecture
To build high-performing RAG systems with Haystack, you need to understand its fundamental building blocks. Haystack’s architecture is modular and intuitive, revolving around three key concepts: Nodes, Pipelines, and Agents.
Think of it as a factory assembly line. Your raw material is unstructured information, and the finished product is a precise, context-aware answer generated by an LLM. Every component in Haystack has a distinct job in this production process, especially in the crucial retrieval stage.
Nodes: The Specialized Workstations
Nodes are the individual workstations on our RAG assembly line. Each one performs a specific, specialized task—they're the core processing units of any Haystack system. A Node might be responsible for fetching data, cleaning it, embedding it, or retrieving it.
When building a RAG system, you'll work with these essential Nodes:
- DocumentStore: This is the warehouse for your knowledge base. It’s where all your indexed documents and their vector representations are stored and managed. It connects to various backends, from traditional options like Elasticsearch to dedicated vector databases.
- Retriever: This is the forklift operator responsible for finding relevant information. When a query comes in, its job is to search the entire DocumentStore and pull a set of candidate documents most likely to contain the answer. Optimizing this node is key to RAG success.
- Generator (or PromptNode): This is the final assembly station. It takes the relevant documents found by the Retriever and feeds them, along with the original query, into a Large Language Model (LLM) to craft the final, coherent answer.
Pipelines: The Conveyor Belt System
If Nodes are the workstations, a Pipeline is the conveyor belt connecting them. It defines the exact path that data follows from one Node to the next. This is where the power of the Haystack framework shines for RAG: you can design completely custom retrieval workflows by arranging Nodes in any sequence you need.
For a standard RAG workflow, a simple Pipeline might send a query first to a Retriever, which then passes its findings on to a Generator. This linear flow ensures each step builds on the last. This flexibility is crucial for building robust RAG applications. For anyone managing complex data ecosystems, understanding how these pipelines integrate with different platforms is key; you can explore advanced options for managing vector data in our detailed look at Databricks Vector Search.
A well-designed Pipeline is more than just a data path; it's the logical blueprint of your entire RAG application. It dictates how information is processed, refined, and ultimately used to generate answers, making it the most critical element for ensuring retrieval accuracy and efficiency.
Mastering how these components connect gives you precise control over your system's behavior. This lets you fine-tune every part of the retrieval and generation process, helping you move from a basic prototype to a production-ready application that delivers reliable, data-grounded insights.
How to Build Your First RAG Pipeline
Let's move from theory to a running application. Building your first Retrieval-Augmented Generation (RAG) pipeline with Haystack is surprisingly straightforward. The process boils down to preparing your data for optimal retrieval, storing it in an accessible way, and then wiring up components to process queries.
We'll walk through the essential steps to get a basic RAG system up and running. Think of this as a foundation you can later optimize for improved retrieval accuracy.
This flow chart gives you a bird's-eye view of how the pieces fit together in the Haystack architecture.
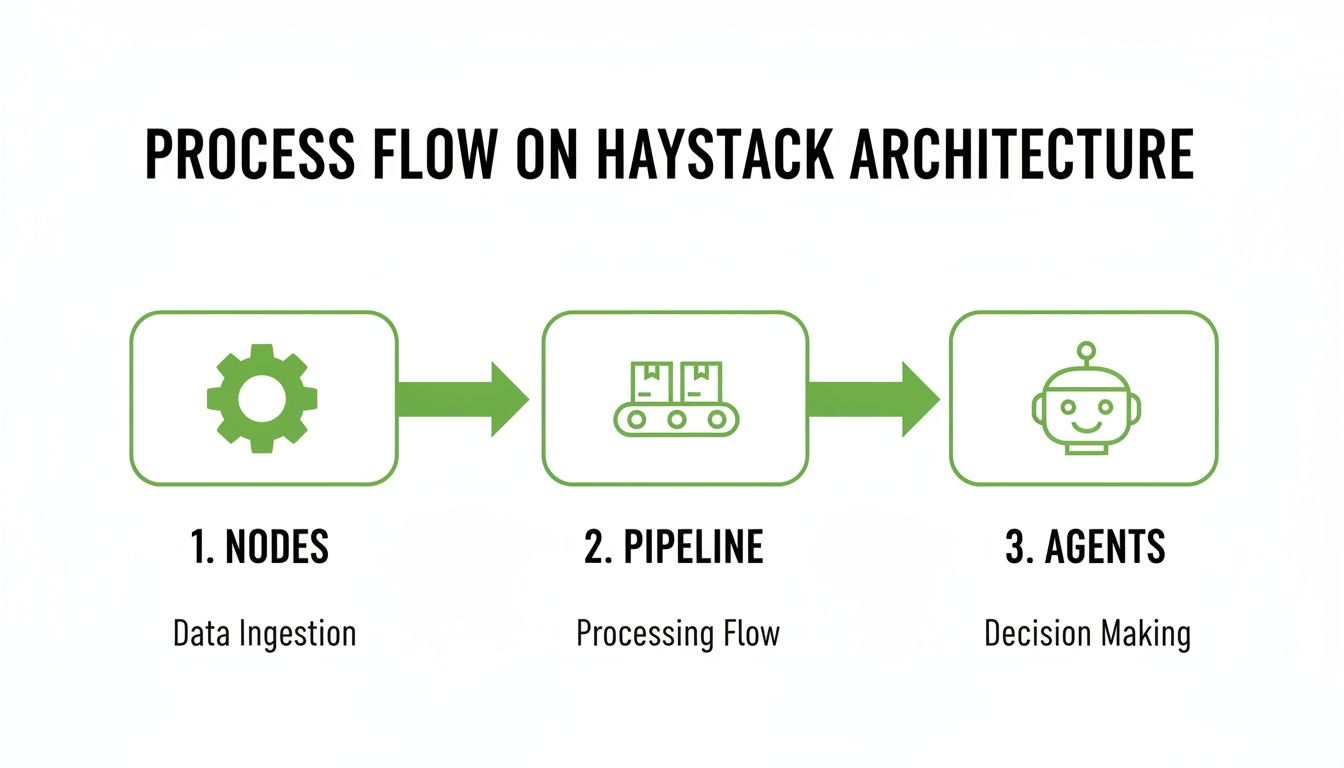
As you can see, data moves logically from Nodes (where the work happens) through Pipelines (the workflow) and is finally used by Agents to make decisions. It’s a clean, modular setup.
Step 1: Prepare Your Data for Ingestion
Before your RAG system can retrieve anything, you must feed it high-quality, well-structured information. Your first job is to take source documents—PDFs, text files, or markdown pages—and prepare them for indexing using a Preprocessor node.
The Preprocessor cleans your text and, more importantly, splits documents into smaller, manageable chunks. This is the most critical step for retrieval accuracy. If chunks are too large, they introduce noise and irrelevant details into the context. If they are too small, they lack the surrounding context needed for the LLM to generate a useful answer.
Actionable Insight: Don't accept default chunking settings. For better RAG retrieval, experiment with different splitting strategies (e.g., by sentence, paragraph, or fixed token count) and test various overlap sizes to ensure semantic continuity between chunks. The quality of your retrieval is directly tied to the quality of your chunks.
Tools like ChunkForge were built for this. It lets you visually inspect how documents are divided, so you can fine-tune the process and ensure every chunk is optimized for RAG with meaningful context.
Step 2: Index Documents in a DocumentStore
Once your documents are optimally chunked, they need a home. That home is the DocumentStore, which serves as the central database for your knowledge base. Haystack supports everything from simple in-memory stores for quick prototyping to production-grade vector databases like Pinecone, Weaviate, or OpenSearch.
When you write your prepared chunks to the DocumentStore, they are converted into numerical vectors called embeddings. This process enables an EmbeddingRetriever to find documents based on semantic meaning, not just keyword matches, which is the cornerstone of effective RAG.
Step 3: Configure the Retrieval and Generation Nodes
With your data indexed, it's time to build the active part of your pipeline. This means setting up two crucial nodes: the Retriever and the Generator (often wrapped in a PromptNode).
- Choose a Retriever: For semantic search, the
EmbeddingRetrieveris the standard choice. You'll connect it to an embedding model—often from Hugging Face's sentence-transformers library—that is well-suited to the language and domain of your data. The choice of model directly impacts retrieval quality. - Set Up a PromptNode: This node acts as the bridge between your retriever and your LLM. Here, you'll craft a prompt template that instructs the LLM on how to use the retrieved context. Your template will have placeholders for the user's question and for the relevant documents fetched by the
Retriever. - Connect a Generator: The
PromptNodesends its formatted prompt to aGenerator. This is your pipeline's connection to an LLM like GPT-4. TheGeneratorexecutes the prompt and produces the final, context-grounded answer.
This modular setup is one of Haystack's greatest strengths for RAG. You can easily swap out different retrievers, embedding models, or prompt templates with minimal code changes, making it simple to experiment and find the optimal configuration for your retrieval system.
Strategies for Improving Retrieval Accuracy

Getting a basic Haystack pipeline running is the first step. The real value comes from optimizing it. A simple RAG setup provides answers, but refining the retrieval process is what delivers the consistently accurate and relevant results needed for a production-grade application. It’s how you build a system users can trust.
This journey starts by moving beyond a single retrieval method. While semantic search is powerful, it can struggle with specific identifiers like product codes, technical jargon, or names. This is where a more sophisticated approach called hybrid search becomes a game-changer for retrieval.
Combining Keyword and Semantic Search
Hybrid search is a powerful strategy to improve retrieval by getting the best of both worlds. It combines two distinct methods to cast a wider, more accurate net.
- Keyword Search (BM25): This classic search method excels at finding documents with exact keyword matches. It's fast, efficient, and perfect for queries where literal terms are critical. Use Haystack's
BM25Retrieverfor this. - Semantic Search (Embedding-based): This method understands the meaning behind a query, finding relevant documents even without exact word matches. It grasps the underlying context and intent. The
EmbeddingRetrieverhandles this.
By running both retrievers in your pipeline, you can capture both literal keyword hits and conceptual semantic matches. This dual approach dramatically reduces the risk of your RAG system missing a crucial piece of information.
Refining Results with Rerankers and Filtering
Once your retrievers gather a pool of candidate documents, the next step is to refine that pool. Getting many documents is easy; getting the best ones to the top is the real challenge.
Enter the reranker. A reranker is a specialized node that takes the initial search results and re-sorts them using a more powerful, computationally intensive model. It acts as a final quality check, pushing the most relevant documents to the top before they are passed to the LLM. This step is vital for reducing noise and focusing the language model's attention on the best possible context.
Another powerful tactic is metadata filtering. By enriching your documents with tags, dates, or categories during ingestion, you can narrow the search with surgical precision. For instance, you could instruct your pipeline to only retrieve documents created after a certain date or tagged with a specific project. Our guide on RAG pipeline optimization dives deeper into these techniques.
Actionable Insight: The goal of retrieval isn't just to find relevant documents—it's to deliver the most concise and accurate context possible to the LLM. Every optimization, from hybrid search to reranking, is a step toward minimizing ambiguity and maximizing the quality of the final generated answer.
Measuring Performance with Evaluation Tools
You can't improve what you don't measure. Haystack includes built-in evaluation tools that allow you to quantitatively score your pipeline's retrieval performance.
By creating a set of "ground truth" question-and-answer pairs, you can run experiments and track key metrics like recall (did the retriever find the right document?) and Mean Reciprocal Rank (MRR) to assess the ranking of relevant documents.
This data-driven approach enables informed decisions. You can swap out embedding models, tweak reranker settings, or adjust retriever weights, all while measuring the direct impact on accuracy. This iterative cycle of testing, measuring, and refining is the key to building a robust and trustworthy RAG system with the Haystack search engine.
Comparing Haystack to LangChain and LlamaIndex
<iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube.com/embed/UuFhhNTwj8E" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>Choosing the right framework for your LLM application is a critical decision. While Haystack, LangChain, and LlamaIndex are often mentioned together, they have different philosophies and are optimized for different tasks, particularly concerning RAG.
Understanding their core differences is key to selecting the best tool for building and optimizing your retrieval systems.
Core Philosophy and Strengths
The primary distinction lies in their design focus.
Haystack was built from the ground up with a production-first mindset for retrieval systems. It's designed for creating robust, scalable, and observable RAG pipelines. It provides fine-grained control over every component, from the retriever to the reranker, and includes strong evaluation tools to measure and improve retrieval performance. This makes it an excellent choice for serious, enterprise-grade RAG applications.
LangChain is a general-purpose framework designed for versatility and rapid prototyping. It offers a vast library of integrations and pre-built "chains" for quickly assembling complex workflows and agent-based systems. Its main strength is its breadth, making it a great sandbox for exploring a wide range of LLM capabilities beyond just RAG.
LlamaIndex is hyper-focused on the data ingestion and indexing side of RAG. It provides a rich set of data connectors and advanced indexing strategies to optimize how data is structured for retrieval. If your main challenge is wrangling complex, unstructured data and preparing it for a RAG system, LlamaIndex offers specialized tools.
This kind of specialization is a winning strategy. Just look at the Yandex search engine—it commands 2.16% of the global market not by competing with Google everywhere, but by mastering the nuances of the Cyrillic alphabet, a focus general-purpose engines can't easily match. Similarly, Haystack allows you to build highly tailored retrieval systems for specific data domains, giving you precision where a one-size-fits-all approach falls short. You can explore more on search engine market dynamics in this research from Statista.
Choosing between these frameworks isn't about which one is "best." It’s about matching the tool to your priority. Do you need to build a scalable, production-ready retrieval system (Haystack), rapidly prototype various LLM apps (LangChain), or master complex data ingestion for RAG (LlamaIndex)?
Haystack vs LangChain vs LlamaIndex
Here’s a high-level comparison to guide your decision based on your project's primary goal.
| Framework | Core Philosophy | Ideal Use Case | Key Strength |
|---|---|---|---|
| Haystack | Production-first, component-based, and scalable. | Building enterprise-grade semantic search & RAG systems. | Robustness, observability, and fine-grained pipeline control. |
| LangChain | Versatile, general-purpose, and rapid experimentation. | Prototyping a wide variety of LLM-powered applications. | Massive library of integrations and pre-built "chains". |
| LlamaIndex | Data-centric, focused on ingestion and indexing. | Optimizing data preparation for complex RAG systems. | Advanced data connectors and sophisticated indexing strategies. |
Each of these frameworks offers a powerful way to build with LLMs. Your project's specific needs—from initial R&D all the way to long-term maintenance and scaling—should be your ultimate guide.
Common Questions About Haystack
When you're first exploring a new framework like Haystack, you're bound to have questions. Understanding the fundamentals is key to building effective RAG systems and avoiding common pitfalls.
Let's address a few of the most common questions developers have when working with the Haystack search engine.
Is Haystack a Standalone Search Engine?
No. This is a common misconception. Haystack is not a self-contained search engine like Elasticsearch. It does not store your data itself.
Think of Haystack as the conductor of an orchestra. It's an open-source framework for building intelligent search applications. It provides the Nodes and Pipelines that orchestrate the flow of information between your data (stored in a separate document or vector store) and a language model. Its purpose is to give you the tools to create sophisticated semantic search and Retrieval-Augmented Generation (RAG) systems.
How Are Retrievers and Readers Different?
In Haystack, Retrievers and Readers are distinct components that work together to deliver accurate answers efficiently, though modern RAG pipelines often favor a Retriever-plus-Generator architecture.
-
The Retriever: Its sole job is to be fast and comprehensive. It scans the entire
DocumentStoreto quickly pull a broad list of documents that might be relevant to the query. It casts a wide net, prioritizing recall to ensure no potential answer is missed. This is the core of the "R" in RAG. -
The Reader: This component performs a more detailed analysis. It takes the pre-filtered list of documents from the Retriever and uses a language model to pinpoint and extract the exact answer from within the text. This is often used for extractive Question Answering.
A simple way to remember it: The Retriever is the fast scout that finds potential documents, while the Reader (or Generator) is the expert analyst that extracts or synthesizes the final answer. This two-step process is crucial for an efficient and accurate Haystack search engine.
Can Haystack Use Models Like GPT-4?
Yes, absolutely. One of Haystack's key features is that it’s model-agnostic, giving you the freedom to plug in whichever Large Language Model (LLM) best suits your project.
Haystack provides clean integrations for a wide range of models. You can easily connect to proprietary APIs from providers like OpenAI (for GPT-4 and others), Cohere, and Anthropic. It also fully supports open-source models from hubs like Hugging Face.
Swapping models in your pipeline is as simple as changing a component like the PromptNode or Generator. This makes it incredibly easy to experiment with different models to find the perfect balance of performance, cost, and features for your application.
Ready to create perfectly optimized chunks for your Haystack pipelines? ChunkForge is a contextual document studio designed to convert your documents into RAG-ready assets. With visual overlays, deep metadata enrichment, and multiple chunking strategies, you can ensure every piece of information fed into your system is primed for the highest retrieval accuracy. Start your free trial at https://chunkforge.com and see the difference for yourself.