
A Practical Guide to Semantics in NLP for Advanced RAG Systems
Unlock powerful RAG pipelines with this deep dive into semantics in NLP. Learn core concepts, methods, and actionable strategies for building smarter AI.

When we talk about semantics in NLP, we're really talking about teaching a machine to grasp the meaning behind our words, not just the words themselves. It’s about understanding context, how words relate to each other, and what a person is actually trying to accomplish. For developers building Retrieval Augmented Generation (RAG) systems, mastering semantics is the key to moving beyond simple keyword search and enabling truly intelligent information retrieval.
The Semantic Revolution: From Keywords to Context

If you've ever built a Retrieval Augmented Generation (RAG) pipeline, you know its most common point of failure all too well: naive retrieval. A user asks a complex question, and the system pulls up completely irrelevant documents because it got hung up on a few keywords instead of understanding the query's actual meaning. This is precisely the problem that semantics in NLP is designed to solve.
This isn't just theory; it's a practical, fundamental shift from the old world of keyword matching to a new one of genuine contextual understanding. While syntax is all about the grammatical rules—how you arrange words in a sentence—semantics goes much deeper to figure out the intended message.
Why Meaning Matters More Than Matching
Think of it this way: syntax is like assembling a car's parts correctly. Semantics is understanding where that car needs to go.
A system stuck on syntax might see "bank account" and "river bank" as similar because they share the word "bank." A semantically aware system, on the other hand, immediately gets the huge difference in meaning based on the words surrounding them. This distinction is the engine behind modern AI that can reason, retrieve, and respond with real precision.
For RAG systems, this isn't just a nice-to-have; it's a must-have. A strong semantic foundation is what allows a retriever to find documents that answer a query's intent, even when the keywords don't match.
The essence of semantic search lies in its ability to understand the intent and contextual nuances behind user queries, transforming the search experience from a simplistic keyword match to a sophisticated, intent-driven interaction.
The Evolution of Understanding
Getting to this level of semantic understanding has been a long road. The journey started decades ago with symbolic, rule-based systems. In the 1970s, early efforts involved manually building out ontologies to structure knowledge—a painstaking process. The 1980s saw a shift toward statistical methods, which was a major step forward.
By 2001, semantic analysis had progressed enough for researchers to successfully use a one-billion-word internet corpus for complex tasks like word sense disambiguation. This evolution from just matching words to truly grasping intent is what makes today’s powerful AI possible.
To see just how widespread this impact is, this guide on Top Natural Language Processing (NLP) Applications offers a great look at its practical uses across different industries.
Core Pillars of Semantic Representation
To build a high-performing RAG system, we have to translate the beautiful mess of human language into something a machine can actually compute. This translation process is called semantic representation. Think of it as creating a "meaning map" for your data—one that a computer can navigate to find what it needs.
The whole point isn't just to store words; it's to capture the complex web of relationships, context, and intent hiding behind them. A high-quality representation is the foundation of retrieval. When a user asks a question, the RAG system converts it into a similar representation and uses that "map coordinate" to find the most relevant information. The better the map, the better the retrieval.
Embeddings: The Language of Meaning Maps
The most common way we create these maps today is with embeddings. In simple terms, embeddings are just lists of numbers (vectors) that represent text. The magic is that words and sentences with similar meanings get assigned coordinates that are close to each other on this vast map.
This proximity allows an algorithm to connect concepts, even when the exact keywords are missing. A query about "workplace safety protocols" can instantly find a document talking about "on-the-job hazard prevention" because their embeddings occupy a similar neighborhood. For RAG, this is the core mechanism for moving beyond literal keyword search to conceptual search.
The real game-changer arrived in 2013 with Word2Vec. This was the moment we could mathematically capture relationships like "king is to queen as man is to woman" just by looking at the geometry of their vectors. It laid the groundwork for the powerful, context-aware embeddings we rely on today.
Knowledge Graphs: Structuring Factual Reality
Embeddings are fantastic for understanding conceptual similarity, but they can get a little fuzzy with hard facts and explicit relationships. That’s where Knowledge Graphs (KGs) step in. KGs are all about structure, representing information as a network of entities (nodes) and the relationships between them (edges).
It’s like a database of facts:
- Entity: "Elon Musk"
- Entity: "Tesla, Inc."
- Relationship: "is the CEO of"
For a RAG system, a KG provides a source of verifiable truth. A question like, "Who is the CEO of Tesla?" doesn't just trigger a search for similar documents. Instead, the system can follow the "is the CEO of" edge from the "Tesla, Inc." node directly to the "Elon Musk" node for a precise answer. This is an incredibly powerful retrieval method for fact-based Q&A. Getting this right often requires advanced tools for pulling structured data out of messy documents, which is a core part of Intelligent Document Processing (IDP).
Semantic Parsing: For Precision Queries
A more specialized but extremely powerful technique is semantic parsing. This process translates a user's natural language question directly into a formal, logical query language, like SQL. Instead of finding similar text, it builds a precise command for a machine to execute.
For instance, "Show me all transactions over $500 from last week" gets turned into an actual database query. This is a must-have for RAG systems built on top of structured databases, as it provides a direct retrieval mechanism for users asking complex questions about data using simple, everyday language.
To help you decide which approach to focus on, this table breaks down the core methods and their best-fit applications in RAG systems.
Comparing Semantic Representation Methods
| Method | Core Idea | Best For RAG | Primary Challenge |
|---|---|---|---|
| Embeddings | Represent text as numerical vectors in a "meaning space." | Broad, conceptual, or "fuzzy" queries where keywords might not match. | Can struggle to distinguish subtle nuances or verify hard facts. |
| Knowledge Graphs | Model data as a network of entities and their relationships. | Fact-based questions and queries that require navigating explicit connections. | Requires significant effort to build and maintain the graph accurately. |
| Semantic Parsing | Translate natural language directly into a formal query language (e.g., SQL). | Systems built on structured databases where users need to query data precisely. | Limited to the domain of the underlying structured data; less flexible. |
Each method has its place, and the strongest RAG systems often blend them to handle different types of queries effectively.
By combining these representation methods, you can build a multi-faceted retrieval system. Embeddings handle the fuzzy, conceptual queries, while knowledge graphs and parsing provide the factual and structured backbone, giving your RAG pipeline the best of both worlds. The way you prepare your documents is key, and our guide on understanding semantic chunking offers practical strategies for this initial step.
How Transformers Finally Cracked Deep Contextual Understanding
For a long time, NLP models had a fundamental blind spot. They processed text sequentially, like reading a book one word at a time, either left-to-right or right-to-left. This created a serious "memory" problem. By the time a model got to the end of a long sentence, its understanding of the beginning was already fading. This made it incredibly difficult to grasp the full picture, especially when dealing with ambiguous language.
This one-way-street approach was a massive bottleneck for information retrieval. If your system can't fully decipher what a user is asking, how can it possibly find the right document? This is where the Transformer architecture completely flipped the script, shifting NLP from a linear, word-by-word process to a truly holistic one.
Seeing the Whole Picture at Once
Think of it like a detective at a crime scene. Older models were like a detective who could only look at one piece of evidence at a time, in a fixed order, trying to piece it all together from memory. A Transformer, on the other hand, is like a detective who can see the entire room at once—the victim, the weapon, the open window, the footprints—and instantly understand how every single element relates to every other element.
This is the magic behind the attention mechanism, the engine that drives Transformers. It allows the model to weigh the importance of every word in a sentence against all the others, regardless of their position. This ability to look forwards and backwards simultaneously is what we call bidirectional context.
For a RAG system, this is a game-changer. Bidirectional context means the model can finally understand the real intent behind a query like, "What is the capital of Turkey?" It won't get sidetracked by documents talking about the bird because it grasps that "capital" relates directly to the country "Turkey," leading to far more accurate retrieval.
BERT: The Watershed Moment for Semantics
Everything changed in 2018 when Google introduced BERT (Bidirectional Encoder Representations from Transformers). BERT wasn't just an incremental improvement; it was a fundamental shift in how machines understand language. By pre-training on colossal amounts of text, it learned to analyze each word in relation to all the others in a sentence, capturing nuance and context in a way that was previously impossible. This bidirectional approach proved to be a massive leap over older, unidirectional models.
You can learn more about this pivotal moment in the history of Natural Language Processing. BERT, and the models it inspired (like RoBERTa and ALBERT), came with a rich, built-in understanding of language that could then be fine-tuned for specific jobs.
What This Means for Your RAG System
This leap in contextual understanding has a direct and powerful impact on building better retrieval systems. Here’s what it unlocks:
- Smarter Query Understanding: The model generates a much more precise vector representation (embedding) for a user's query because it captures the complete intent, not just a bag of keywords.
- More Coherent Document Chunking: When you're indexing documents, Transformers can identify semantically complete chunks. This ensures that the context needed to answer a potential question isn't accidentally split across two different pieces.
- Deeper Semantic Matching: The model gets exponentially better at matching a query's embedding to the right document chunks, even when they use completely different words to express the same idea.
When you build your RAG pipeline with a Transformer-based model, you're giving it a retriever that doesn't just match words—it understands meaning. This is the foundation for moving beyond basic keyword search and building systems that can genuinely reason with information.
Actionable Semantic Strategies for RAG Pipelines
Theory is great, but a high-performing Retrieval Augmented Generation (RAG) system is built in the trenches of practical implementation. Once you move past the abstract concepts, you'll find the biggest gains in retrieval accuracy come from the document processing and chunking stage. How you prep your data directly controls the quality of information your retriever can find.
A common starting point is simple, fixed-size chunking—just slicing documents into uniform blocks of text. The problem is, this approach is fundamentally naive. It ignores the underlying meaning and often splits a coherent thought or a critical piece of context right down the middle. This creates fragmented, semantically incomplete chunks that can cripple retrieval performance. To build a system that actually works, you have to respect the semantics in NLP from the very beginning.
This flow shows how our models have gotten smarter over time, moving from a simple one-way street of understanding language to the much more nuanced approach needed for today's RAG pipelines.
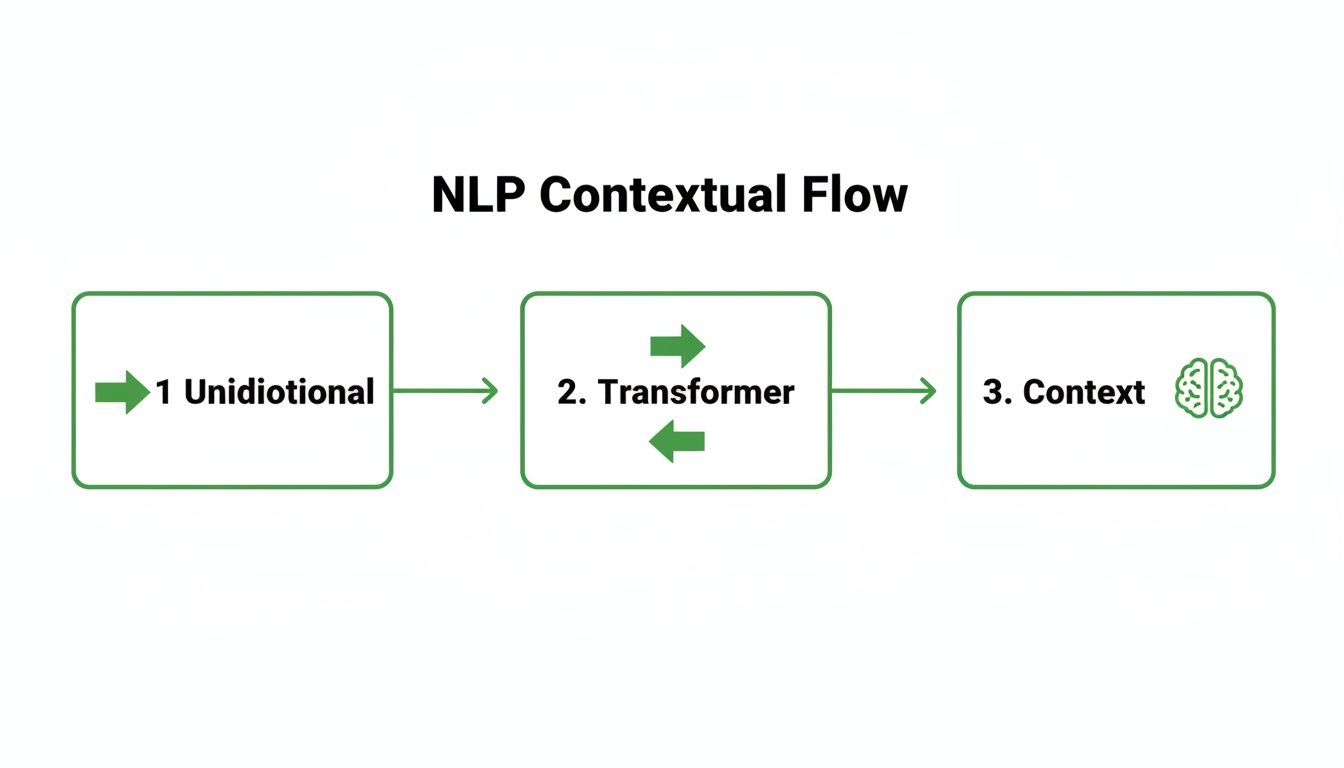
The key takeaway here is the leap from unidirectional models to Transformer-based architectures. That shift is what gives us the deep contextual understanding that makes powerful semantic retrieval possible.
Beyond Fixed-Size Splits: Semantic Chunking
The first major upgrade for your retrieval pipeline should be semantic chunking. Instead of blindly chopping text based on character or token counts, this technique groups text based on thematic coherence. It actually uses the embeddings we discussed earlier to find natural breakpoints where the topic shifts, making sure each chunk represents a self-contained, meaningful idea.
Think about a user manual. One section might discuss "battery installation," and the next might cover "software setup." Semantic chunking is smart enough to create a boundary right between those two distinct topics, even if a fixed-size split would have sliced the installation instructions in half. The result? Chunks that are far more likely to contain the complete answer to a user's question.
By grouping text based on conceptual similarity, semantic chunking ensures that each indexed document is a coherent unit of meaning. This dramatically increases the chances that a user's query vector will match a chunk containing a complete, relevant answer, rather than just a fragment.
Enriching Chunks with Deep Metadata
Creating better chunks is only half the battle. You also need to enrich them with deep metadata to create multiple pathways for your retriever to find them. Think of it as adding a rich set of searchable tags to every piece of your knowledge base, making your retrieval far more robust.
Here’s what effective metadata enrichment looks like in practice for RAG:
- Automated Summaries: Generate a crisp, one-sentence summary for every chunk. This gives the retriever a bird's-eye view of the content, ideal for matching high-level queries.
- Keyword Extraction: Identify and tag the most important keywords or concepts within the chunk. This allows for hybrid search strategies that combine keyword precision with semantic breadth.
- Entity Tagging: Use Named Entity Recognition (NER) to find and label people, organizations, locations, and other specific entities. This enables incredibly precise, filtered retrieval. If you want to go deeper, you can explore the nuances of Named Entity Recognition in NLP to see how it can be applied.
This metadata isn't just passive information; it becomes an active part of the retrieval process, giving the system more signals to work with than just the raw text.
Building a Multi-Vector Retrieval System
Once your chunks are properly enriched, you can build a much more powerful retrieval architecture: multi-vector retrieval. Instead of creating a single embedding for the entire chunk, you create separate, specialized embeddings for different parts of its data. This strategy acknowledges that a single query can have multiple facets—some broad, some specific.
A common and highly effective setup involves creating two primary vectors for each chunk:
- The Summary Vector: An embedding made from the concise, one-sentence summary. This vector is fantastic at matching broad, conceptual queries where a user is just trying to find the right topic.
- The Full-Text Vector: An embedding of the full, original text of the chunk. This one excels at finding specific details, keywords, or nuanced phrases buried deep within the content.
When a user submits a query, the system embeds their question and searches against both the summary vectors and the full-text vectors. By retrieving candidates from these two distinct "meaning maps," you cast a much wider net and dramatically improve your odds of finding the most relevant information. It’s a hybrid approach that combines the best of high-level topic matching with fine-grained detail retrieval, making your RAG pipeline significantly more robust and accurate.
Evaluating and Benchmarking Semantic Retrieval
<iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube.com/embed/fFt4kR4ntAA" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>So, you've implemented sophisticated semantic strategies in your RAG pipeline. That's a huge step, but it’s only half the battle. Now comes the hard part: proving your changes actually improved retrieval quality.
Without a solid evaluation framework, you’re flying blind. You can't quantify improvements, justify the engineering effort, or make data-driven decisions about what to do next. To really understand how semantics in NLP impacts your RAG system, you have to move beyond simplistic accuracy scores.
It's not enough to know if a retrieved document was "correct." The real questions are: Did we find the best answer? Was it at the top of the list, or buried on page two? A good evaluation pipeline gives you clear answers, so you can stop guessing and start refining your system with confidence.
Key Metrics for RAG Retrieval Quality
To really get a handle on your retrieval performance, you need metrics that understand the nuance of a ranked list. Here are a few of the most critical ones:
-
Mean Reciprocal Rank (MRR): This one is simple but incredibly useful. MRR cares about one thing: where did the first right answer show up? If the first relevant document was in the third spot, the reciprocal rank is 1/3. This makes it perfect for tasks like Q&A, where getting a single, correct answer to the user as fast as possible is all that matters.
-
Normalized Discounted Cumulative Gain (NDCG): A bit more sophisticated, NDCG looks at the entire ranked list. It rewards you for putting highly relevant documents at the top and penalizes you for burying them. It's the right metric when multiple documents could be good answers and their relative order is important.
-
Context Relevance & Precision: These are crucial for RAG systems. Context Relevance asks: does the retrieved chunk actually contain the specific fact needed to answer the query? Context Precision, on the other hand, asks: how much of that chunk is useful versus how much is just noise? High precision is gold because it makes the LLM’s job of generating an answer much, much easier.
A classic RAG failure is retrieving a document that’s about the right topic but doesn't contain the actual answer. Think of asking for a specific financial figure and getting a general company report. This is a "relevance mismatch," and metrics like NDCG and Context Relevance are designed to sniff out and penalize this exact problem.
Key RAG Retrieval Evaluation Metrics
Here’s a quick summary of the metrics you’ll want to keep in your back pocket for evaluating any retrieval system.
| Metric | What It Measures | When to Use It |
|---|---|---|
| Mean Reciprocal Rank (MRR) | The rank of the first correct answer. | Best for known-item search or Q&A where finding one right answer quickly is the goal. |
| NDCG | The quality of the entire ranked list, prioritizing top results and graded relevance. | Ideal when multiple documents can be relevant and their order matters. |
| Context Relevance | Whether the retrieved chunk actually contains the information needed. | Essential for RAG to ensure the context passed to the LLM is sufficient. |
| Context Precision | The signal-to-noise ratio within the retrieved context. | Use to optimize chunking and reduce the cognitive load on the LLM generator. |
Choosing the right metric depends entirely on what you define as "success" for your specific application. A combination of these often tells the most complete story.
Standardized Benchmarks for Semantic Search
Evaluating on your own data is non-negotiable, but to see how your system stacks up against the wider world, you need to test it on public benchmarks. These standardized datasets and leaderboards provide an objective yardstick for measuring performance against state-of-the-art models.
Two of the heavyweights in this space are:
- BEIR (Benchmarking IR): This is a fantastic, diverse collection of datasets from different domains. It’s perfect for seeing how well your retrieval model generalizes beyond its training data.
- MS MARCO: A massive dataset built from real Bing search queries. It’s the go-to standard for evaluating passage ranking and question-answering systems.
Benchmarking regularly helps you track progress, spot weaknesses, and prove that your semantic enhancements are genuinely moving the needle. It's this data-driven discipline that turns a good RAG prototype into a great production system. If you want to get into the nitty-gritty of building one, our guide to designing a complete RAG pipeline walks through the entire process, from ingestion to evaluation.
Your Semantic RAG Blueprint
So, we've journeyed from the old world of simple keyword matching to the sophisticated, contextual understanding that drives modern AI. Now, let's put it all together. How do you actually build a Retrieval Augmented Generation (RAG) pipeline that gets it?
This isn't just theory. Think of this as your high-level checklist for evolving your systems. We're moving them from naive, often clumsy retrieval to something genuinely semantically aware.
The real shift in thinking is realizing that every single step in your pipeline is a chance to inject more meaning. A truly great RAG system isn't the result of one magic algorithm; it's built from a series of deliberate, semantically-driven choices that stack up to create something far more powerful. It’s about chasing the why behind a query, not just the what.
The Core Upgrade Path
Moving from a basic keyword-based RAG to an advanced one is a clear, logical progression. Each upgrade builds on the last, creating a more resilient and accurate retrieval foundation. The aim is to create multiple, rich pathways to the answer so that it doesn't matter how a user phrases their question—you can find the context they need.
Here’s your action plan, broken down into the critical stages:
-
Semantic Document Processing: Your first job is to stop thinking about documents as just long strings of text. Use semantic chunking to create self-contained, meaningful units of information. This is your most important defense against pulling back fragmented, out-of-context garbage.
-
Rich Metadata Enrichment: Never index raw text alone. For every chunk you create, generate summaries, extract keywords, and pull out named entities. This structured metadata acts as a powerful set of additional signals, making your retrieval process more precise and flexible.
-
Multi-Vector Indexing: Why settle for one vector per chunk? Create separate embeddings for different views of your data—one for a concise summary, another for the full-text chunk. This hybrid strategy lets your system match high-level concepts and granular details with equal skill, effectively casting a wider and much smarter net.
-
A Robust Evaluation Framework: You can't fix what you can't measure. You absolutely must implement a solid evaluation pipeline using metrics like NDCG and context relevance. This is the only way to prove your semantic upgrades are actually working and to guide your next set of improvements with hard data.
Investing in semantics in NLP is the most direct path to building more reliable and genuinely useful AI applications. It represents a fundamental shift away from brittle, keyword-dependent systems toward AI that can reason with and understand the vast world of human language.
Consider this blueprint your call to action. It’s time to embrace the power of meaning and start building the next generation of intelligent systems today.
Questions from the Trenches
When you move semantic NLP from the drawing board to a real-world RAG system, theory quickly gives way to practical hurdles. Here are a few of the most common questions that pop up and how to think through them based on hands-on experience.
How Do I Choose the Right Embedding Model?
This is the big one. The secret isn't finding the "best" model, but the right one for your specific data and what you're trying to accomplish.
For general-purpose tasks, a model from the all-MiniLM series is a great, pragmatic starting point. It offers a solid balance of performance and speed. But if you're working with highly specialized text, like financial reports or clinical notes, you absolutely need to benchmark it against a domain-specific model. The difference can be night and day.
Here’s a quick mental checklist:
- Vector Dimensionality: More dimensions can capture more detail, but they also bloat your memory usage and slow things down. A dimension of 384 or 768 is a common and effective sweet spot for most projects.
- Model Size: Smaller models are nimble and fast, but they might not be as sharp. You need to test whether the speed boost is worth a potential dip in retrieval quality. It's always a trade-off.
- Task Alignment: Was the model trained for symmetric tasks (comparing two similar sentences) or asymmetric ones (matching a short query to a long document)? Using a model trained for the wrong kind of task is a classic mistake that can tank your performance.
Is Semantic Chunking Always Better Than Fixed-Size?
Usually, yes. Semantic chunking is designed to keep complete ideas together, which is the whole point of using semantics in the first place. A chunk that respects sentence or paragraph boundaries is almost always going to give a language model better context.
However, it's not a magic bullet. If you're dealing with highly structured documents—think legal contracts with numbered clauses or technical manuals with uniform sections—a simple, well-tuned strategy based on headings or paragraphs can be just as good and a lot less computationally expensive.
My advice? Start with semantic chunking as your default. If it's not working or you have a specific reason to switch (like highly uniform source files), then explore other methods. No matter what, always spot-check your chunks visually. Make sure they actually make sense before you dump them into your vector database.
The biggest failure mode for RAG is fragmented context. A chunk that contains only half of an idea is often worse than no chunk at all, as it can mislead the language model during generation.
Why Are My Semantic Search Results Still Irrelevant?
It’s frustrating when you've done all this work and the results are still off. When semantic search isn't hitting the mark, the culprit is almost always one of these three things:
- Poor Chunking: I'll say it again—fragmented or overly broad chunks are the number one cause of bad results. Your retriever might find the right topic but grab a chunk that misses the specific detail the user actually needs.
- Query-Document Mismatch: Your users are asking questions one way, but your documents are written another. The language is just different. You can bridge this gap by using query expansion techniques or even generating hypothetical questions for each chunk when you index them.
- Garbage In, Garbage Out: No amount of semantic wizardry can fix messy, unclear, or poorly organized source documents. Your RAG pipeline is only as good as the data you feed it. Make sure your content is clean and coherent before it ever gets near an embedding model.
Ready to move beyond manual document prep and build a RAG pipeline that truly understands your content? ChunkForge gives you the tools to create context-aware, retrieval-ready assets from any document. You can explore advanced chunking strategies, enrich your data with deep metadata, and get production-ready chunks in minutes.
Start your free trial at ChunkForge and see the difference for yourself.